What is Load Balancing?
Load balancing lets you spread load over multiple servers. You would want to do this if you were maxing out your CPU or disk IO or network capacity on a particular server.
Alternatives to load balancing include ‘scaling’ vertically. e.g. getting faster or better hardware such as quicker disks, a faster CPU or a fatter network pipe.
Implementing Load Balancing
One simple way to implement load balancing is to split services between servers. e.g. running the web server on one server and the database server on another. This way is easy since there are no data replication issues. e.g. all necessary files are on the web servers, all necessary database data is on the database server.
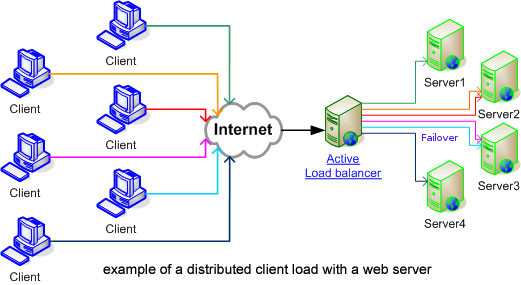
Another common load balancing option is to have multiple front end servers. To distribute requests to multiple servers you could setup multiple IP addresses for a particular domain. Then clients should get all these addresses and to a random one. Spreading the load around.
Another way to distribute requests is to have a single virtual IP (VIP) that all clients use. And for the computer on that ‘virtual’ IP to forward the request to the real servers. eg with haproxy.
People can also implement load balancing via http balancers like mod_proxy_balancer in NGINX or Apache 2.2.
What is Failover?
The goal of failover is to allow work that would normally be done by one server to be done by another server should the regular one fail.
For example, Server A responds to all requests unless it has a hardware failure, or someone trips over its network cable, or the data center it is located in burns to the ground. And if Server A cannot respond to requests, then Server B can take over.
Or if you simply need a service to be highly available, failover allows you to perform maintenance on individual servers (nodes) without taking your service off-line.
For failover server B would ideally be in a separate data center, or if that wasn’t possible you would at least want to try and put it on a separate switch than Server A and on a separate power outlet as well. Basically the more physical separation the better.
For failover server B would ideally be in a separate data center, or if that wasn’t possible you would at least want to try and put it on a separate switch than Server A and on a separate power outlet as well. Basically the more physical separation the better.
Implementing Failover
To implement failover you typically need to have your data replicated across multiple machines. You could do this via rsync+cron for files/directories. And via something like MySQL replication for databases.
One way to trigger the failover is to change the IP address your domain points to. IP address changes can happen within a few minutes of a DNS server update. Though if a client PC is caching an IP then it may take a bit longer for that to notice the change.
What about Shared Storage?
In an ideal world you would have a file system that any server could read/write to and where that filesystem was located on disks spread across multiple servers and where any of those servers or disks could fail and that would not affect the file system’s availability.
In the real world to do this you need a clustered file system. That is a file system that knows it needs to co-ordinate any disk access between other servers in the cluster. To do that you need to have monitoring software (to check when a device goes down) as well as locking software (e.g. DLMs) that ensure that no two servers are writing to the same place, or that one server is not reading something that another server is in the middle of writing.