This article describes the application architecture pattern which is (in general) nothing new, but (from my experience) rarely applied in the Rails world. I’m talking about the nice and simple abstraction – message queue. But let me start by describing the goals I want to achieve and some alternative solutions.
Goals
Split application into a few smaller applications
Smaller applications are easier to reason about. You don’t have to go through 50 classes, you can just read 10, because it’s all you’ve got. When a new developer joins the team he has nice onboarding if you can tell him: “hey, start with this small piece of code, everything you need to know to implement this new feature is encapsulated here”.
Separate code for concepts which are not logically connected
Smaller applications are easier to reason about. You don’t have to go through 50 classes, you can just read 10, because it’s all you’ve got. When a new developer joins the team he has nice onboarding if you can tell him: “hey, start with this small piece of code, everything you need to know to implement this new feature is encapsulated here”.
Use new languages and frameworks
We, developers, want to try and learn new languages, libraries, frameworks and technologies. If you make a small application with a shiny new tool and fail – the consequences are less severe, because you can quickly rewrite this small application. If you are going to make one big application, you will think twice before introducing a new tool. So, in some way, smaller applications minimize the risk.
Solution1 - One database, multiple apps
This is the very first idea which may come to your mind – just point multiple applications to the one shared database. Been there, done that, won’t do that again! Data is associated with validation logic. Either you duplicate this logic in every app or you extract it to Rails engine gem. Both solutions are hard to maintain (think about running migrations…) and you still have strong coupling in your system.
One case when this approach may work – one read-write app and many read-only apps, but I haven’t tried it.
Solution2 - Expose REST API
As Rails devs we are pretty familiar with REST, so we can expose REST API in one of our apps and call this API in the other. This approach has many solid use cases so here I’m just listing some weak points to take into consideration:
- Usually requests in Ruby are blocking – calling app has to wait for the response even if it’s not interested in it.
- Requires authentication – we have to somehow ensure that our internal API is not used… well, externally.
- Everything happens in server process – if you are calling your internal API you may end up using the same server process which is used for handling requests of your “real users”. You would like to give your “real users” priority.
- Calling app has knowledge about receiving app – you have to know which endpoints should be called and which parameters be passed. This introduces coupling.
Solution3 - Message queue
Message queue is a really nice abstraction. Publisher just leaves messages at one end of the “pipe”, consumer reads messages from the other end of the “pipe”. It is asynchronous, because publisher does not wait for his message to be processed. Moreover, it decouples publisher from consumer, because publisher does not care what happens with his message and who will read it.
This architecture is also resistant to outages, at least when we assume that the queue service rarely breaks. If the consumer is not processing messages, nothing prevents publisher from adding more of them to the queue. When consumer starts to function again, it will process messages from the buffer (if they didn’t take all of your memory).
When it shines?
Message queue is really useful if we have some processing which happens out of the main business flow and the main business flow does not have to wait for the results of this processing. The most common example is custom event tracking – own analytics module. We just publish an event and continue execution without slowing anything down.
RabbitMQ
RabbitMQ is a popular choice for message queue service, especially in Rails world. Honestly, I haven’t tried different implementations, because RabbitMQ really has everything I need.
There are Ruby gems for communicating with RabbitMQ and it’s also easy to install and configure.
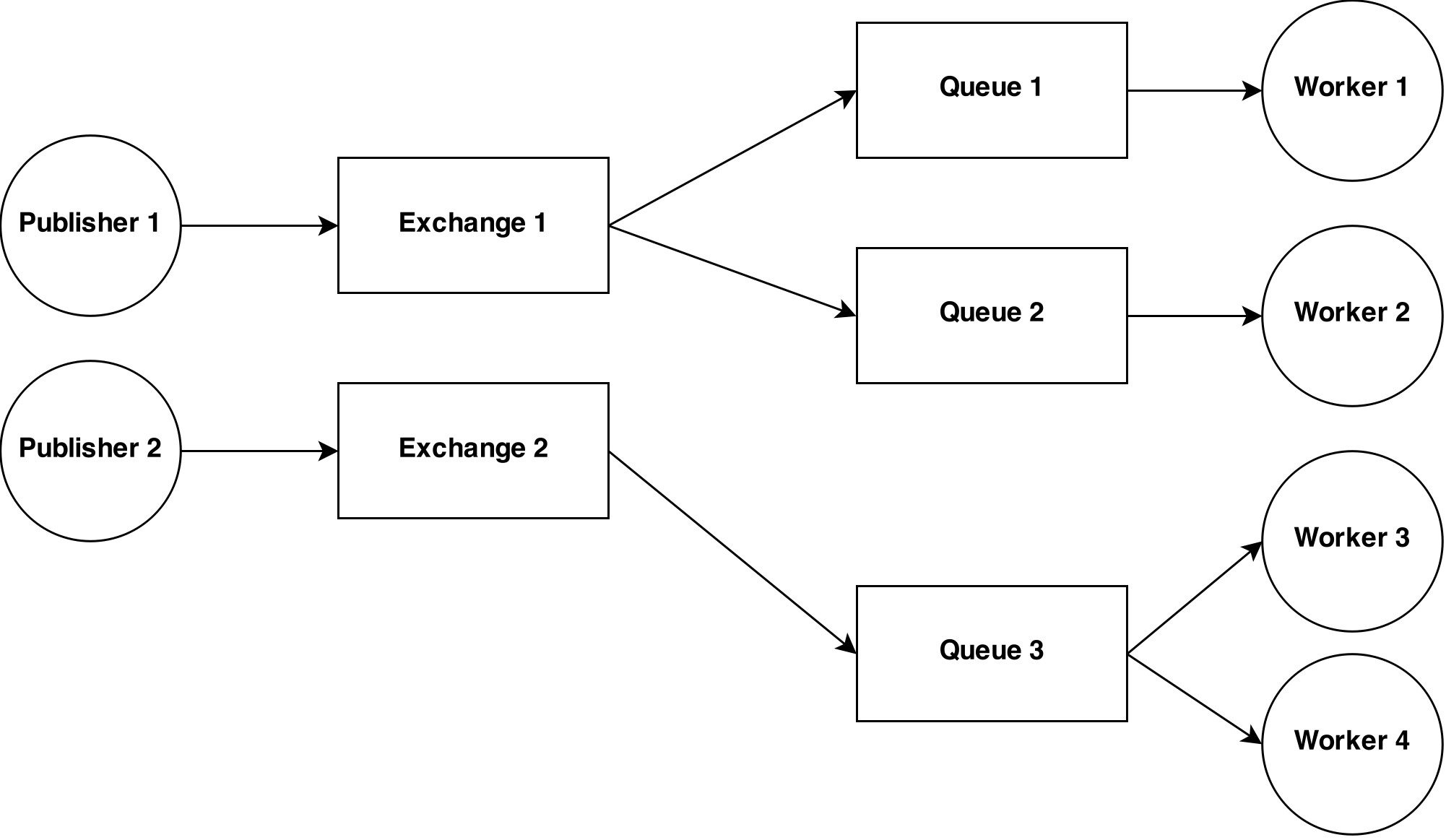
In this diagram there are presented some concepts introduced by RabbitMQ. Publisher leaves messages in the exchange. Then they are routed from the exchange to multiple queues. There are many routing algorithms available – https://www.rabbitmq.com/tutorials/amqp-concepts.html#exchanges
Workers grab messages from queue. If there are multiple workers connected to one queue, they will be load balanced and the message will be delivered only to one of them.
Easy case
If you feel overwhelmed – don’t worry. Here is what you should start with:
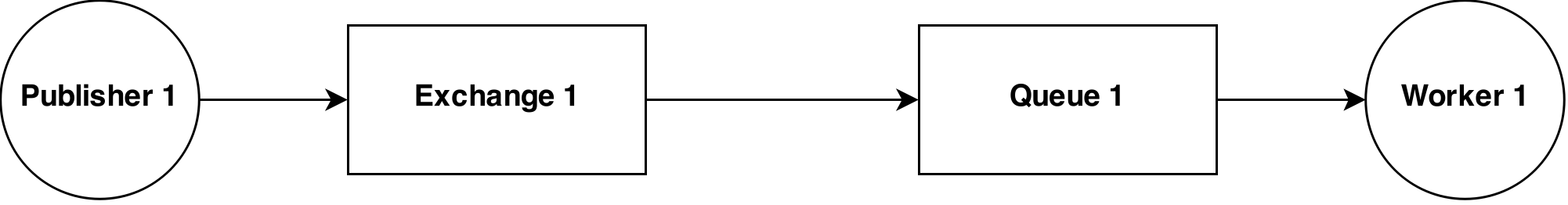
Publishing
Now it’s time for some code. It’s really simple, because integration with RabbitMQ is simple. We will use two gems – bunny and sneakers.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Receiving
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
For details refer to documentation of bunny and sneakers.
If you enjoyed this article you can consider ping me for more details.
So far so good, That’s it!!! See ya!!! :)